
La IA conversacional ya no es un experimento: es una nueva capa de acceso al conocimiento corporativo. Un LLM empresarial bien diseñado permite consultar políticas en segundos, generar minutas con acuerdos y próximos pasos, responder tickets de soporte con evidencia y hasta ejecutar acciones en sistemas internos. La diferencia entre “probar un chatbot” y obtener resultados medibles no está en la moda del modelo, sino en el método: datos confiables, arquitectura correcta, seguridad, evaluación y gobierno continuo.
En este artículo explicamos en lenguaje claro qué es un LLM empresarial, cómo funciona, qué efectos produce al integrarlo en el día a día, y cómo lo construimos en Neural Coders para que sea útil, seguro y escalable. También incorporamos una tabla de ruta de implementación con métricas para que puedas dimensionar tiempos, entregables y resultados esperados.
¿Qué es exactamente un LLM empresarial?
Un LLM (Large Language Model) es un sistema capaz de comprender y generar lenguaje natural. Cuando lo llevamos al mundo corporativo se convierte en un LLM empresarial: un asistente que conoce tu organización, respeta permisos y políticas, cita fuentes y se integra a procesos.
En la práctica, es un “colega experto” que consulta documentos, pregunta a bases de datos, redacta con estilo corporativo y opera con trazabilidad. No reemplaza sistemas; los hace conversables y disminuye la fricción entre personas, procesos y datos.
¿Cómo funciona? Dos ideas clave para técnicos y no técnicos
Primero recupera información confiable de tus repositorios; luego redacta una respuesta clara con esa evidencia. A ese patrón le llamamos RAG (Retrieval-Augmented Generation) y es el punto de partida ideal porque minimiza alucinaciones y permite citar fuentes. ¿Cómo ocurre en la práctica?
- Indexación del conocimiento.
Conectamos a tus repositorios (Docs, PDFs, wikis, tickets, BI, bases de datos). Cada documento se limpia, se segmenta en fragmentos manejables (“chunks”) y se enriquece con metadatos: fecha de vigencia, área responsable, nivel de sensibilidad, versión, idioma, etc. Esos fragmentos se convierten en vectores (embeddings) y se guardan en un índice de búsqueda semántica. - Búsqueda con permisos.
Cuando alguien pregunta, el sistema transforma la consulta y recupera los pasajes más relevantes. Usamos búsqueda híbrida (semántica + tradicional tipo BM25) y técnicas de re-ranking para priorizar lo más útil. Todo esto respeta los permisos: sólo se consideran documentos a los que el usuario tiene acceso (RBAC/ABAC). - Redacción con evidencia.
Con los pasajes seleccionados, el LLM redacta una respuesta en lenguaje claro y agrega citas (enlaces o referencias a la fuente, con su versión). Plantillas de “prompting” garantizan tono, formato y campos obligatorios (por ejemplo, “fuente”, “fecha”, “limitaciones”). - Guardrails (barandales de seguridad).
Antes de devolver la respuesta, pasamos por filtros que previenen inyecciones de prompt, protegen PII (datos personales), evitan lenguaje inadecuado y bloquean solicitudes fuera de política. Si la confianza es baja, el asistente propone pedir confirmación o escalar a un humano.
Sobre esta base, en casos concretos añadimos fine-tuning para afinar estilo, formatos o dominios altamente especializados (por ejemplo, lenguaje jurídico interno). Es importante distinguir qué resuelve y qué no:
- Cuándo sí conviene:
- Estilo ultra consistente (plantillas legales, tono de marca).
- Formularios o salidas muy estructuradas (p. ej., cláusulas con numerales).
- Jerga técnica específica de la organización que el modelo genérico no domina.
- Qué NO resuelve:
- Conocimiento vivo que cambia cada semana (políticas, precios, catálogos). Eso sigue siendo tarea de RAG.
- Problemas de datos sucios o desactualizados: primero hay que limpiar y versionar.
- Falta de permisos o gobierno: el estilo no reemplaza la seguridad.
El fine-tuning puede hacerse con técnicas eficientes (LoRA/Adapters) usando ejemplos curados: pares pregunta-respuesta, documentos anotados y “contrajemplos” para evitar malos hábitos. Siempre lo activamos después de tener RAG estable y sólo si demuestra una mejora medible (consistencia, menor edición humana, menos desviaciones).
Beneficios que empiezan a verse en semanas
- Tiempo: búsquedas que tomaban minutos u horas ahora tardan segundos.
- Consistencia: respuestas alineadas a las políticas vigentes y con citas a la fuente.
- Productividad: menos trabajo manual (compilar, resumir, formatear) y más foco en decisiones.
- Onboarding: nuevos colaboradores aprenden procesos conversando con el asistente.
- Riesgo: permisos por rol, registro de acciones y evidencia reducen errores y ambigüedades.
Nuestra propuesta de infraestructura personalizada
En Neural Coders partimos de una arquitectura modular que adaptamos a cada cliente. El diagrama que usamos —y que personalizamos según tus restricciones y tecnologías— tiene cuatro zonas:
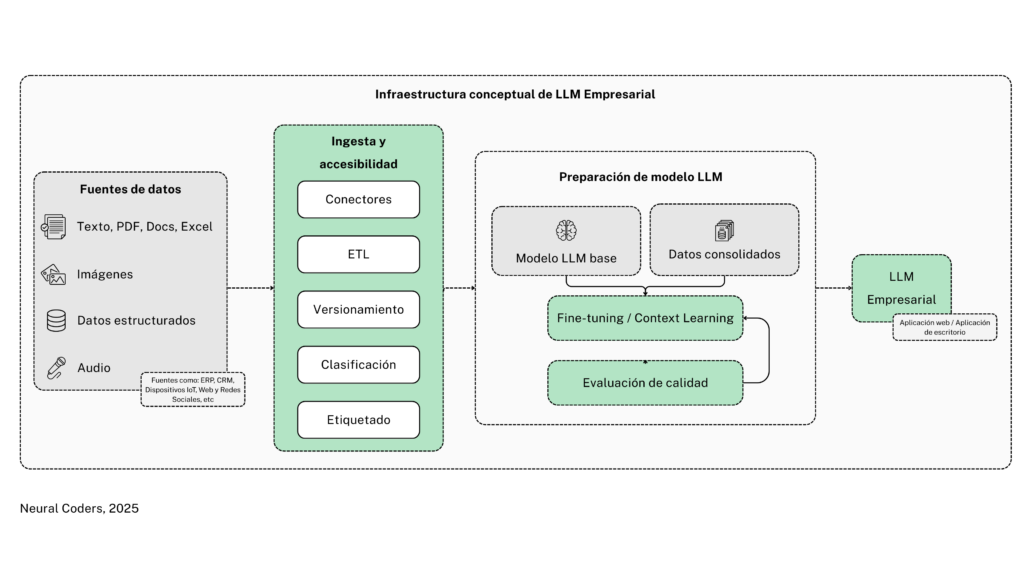
- Fuentes de datos
Documentos (PDF, Docs, correos), imágenes, audio y datos estructurados (ERP, CRM, IoT, plataformas web y redes). - Ingesta, limpieza y normalización
Conectores, ETL, versionamiento, clasificación y etiquetado. Aquí garantizamos calidad y trazabilidad: sabemos qué documento se usó, su vigencia y sensibilidad. - Preparación del modelo
Un modelo base conversa con datos consolidados de la empresa. Comenzamos con RAG; aplicamos fine-tuning sólo si aporta valor medible. Todo pasa por un ciclo de evaluación con preguntas reales. - LLM empresarial y aplicaciones
Exponemos el asistente como app web o de escritorio con SSO, permisos por rol y herramientas para ejecutar acciones (crear ticket, consultar órdenes, generar reportes).
Esta arquitectura evita la trampa del “prototipo simpático” que no escala: la base de datos de conocimiento y la gobernanza se construyen desde el día uno.
Metodología Neural Coders: del caso de uso a la operación sostenida
- Descubrimiento. Identificamos casos de uso con mayor relación impacto/esfuerzo (soporte interno, legal, compras, ventas, operaciones). Definimos KPIs de negocio antes de escribir una línea de código.
- Inventario y calidad de datos. Mapeamos fuentes, sensibilidad, accesos y metadatos. Ejecutamos controles de calidad (completitud, consistencia, duplicados) y políticas de gobernanza (quién ve qué y por qué).
- Arquitectura y seguridad. Diseñamos el plano técnico (on-prem/nube privada/híbrida), cifrado, control de acceso por rol/atributo, auditoría y retención.
- Ingesta y normalización. Construimos pipelines ETL/ELT con versionamiento y etiquetado para habilitar búsquedas precisas y explicables.
- RAG y, si procede, fine-tuning. Empezamos RAG-first. Entrenamos o afinamos sólo cuando hay un caso claro (por ejemplo, plantillas contractuales con estilo corporativo).
- Evaluación y guardrails. Medimos exactitud, cobertura, utilidad y seguridad con un banco de preguntas realista; implementamos filtros y políticas para evitar respuestas fuera de norma.
- Experiencia de usuario e integración. Publicamos el chat corporativo con SSO y permisos; integramos funciones para orquestar acciones (APIs, ERP, CRM, BI).
- LLMOps. Observabilidad, dashboards de calidad, feedback humano, actualización de índices y un plan de mejora continua.
Ruta de implementación y métricas (referencial)
La siguiente tabla resume una ruta típica de 8 a 12 semanas para un primer dominio (por ejemplo, Soporte interno). Los tiempos exactos dependen de volumen y calidad de datos, restricciones de seguridad y alcance de integraciones.
| Fase | Objetivo | Entregables clave | Indicadores de éxito |
|---|---|---|---|
| Descubrimiento (Sem. 1) | Alinear negocio y priorizar casos | Mapa de casos de uso, KPIs, riesgos | Aprobación de alcance; 1–2 casos priorizados |
| Datos & Gobierno (Sem. 1–3) | Garantizar calidad y permisos | Inventario de fuentes, políticas de acceso, esquema de metadatos | % fuentes conectadas; score de calidad ≥ umbral |
| Arquitectura & Seguridad (Sem. 2–4) | Definir despliegue y controles | Blueprint técnico, SSO, RBAC/ABAC, auditoría | Pruebas de acceso, cifrado y logging superadas |
| Ingesta & Normalización (Sem. 3–6) | Construir corpus confiable | Pipelines ETL/ELT, versionamiento, clasificación | Latencia de indexación; cobertura documental |
| RAG & UX inicial (Sem. 5–7) | Habilitar respuestas con evidencia | Índices, prompts, chat corporativo | Exactitud con cita; tiempo a 1ª respuesta |
| Evaluación & Guardrails (Sem. 6–8) | Medir calidad y seguridad | Banco de evaluación, panel de métricas | Tasa de alucinación ↓; utilidad percibida ↑ |
| Integraciones & Agentes (Sem. 7–10) | Ejecutar acciones reales | Funciones: crear ticket, consultar órdenes, etc. | Contención de consultas; automatizaciones/mes |
| LLMOps & Adopción (Sem. 8–12) | Operar y mejorar | Playbooks, dashboards, plan de adopción | Adopción activa; horas ahorradas/mes |
Nota: Tras el primer dominio, la misma base permite escalar a Legal, Compras u Operaciones sin rehacer la infraestructura.
Iniciemos su próximo gran proyecto
Un LLM empresarial no es “otro chat”. Es la forma más rápida y segura de poner el conocimiento de tu organización en la punta de los dedos. La metodología de Neural Coders, datos limpios, arquitectura correcta, RAG-first, evaluación y LLMOps, evita los prototipos que se estancan y habilita resultados medibles: tiempo ahorrado, decisiones más consistentes y menos riesgo operativo.
Si tu empresa quiere pasar de la exploración a la adopción con impacto, conversemos. Diseñamos la infraestructura conceptual a tu medida, integramos el asistente en tus procesos y lo operamos contigo para que deje de ser una promesa y se convierta en ventaja competitiva.


